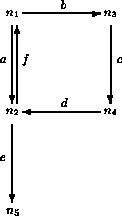

Functional modules define data types and functions on them by means of equational theories whose equations are Church-Rosser and terminating. A mathematical model of the data and the functions is provided by the initial algebra defined by the theory, whose elements consist of equivalence classes of ground terms modulo the equations. Evaluation of any expression to its reduced form using the equations as rewrite rules assigns to each equivalence class a unique canonical representative. Therefore, in a more concrete way we can equivalently think of the initial algebra as consisting of those canonical representatives, that is, of the values to which the functional expressions evaluate by algebraic simplification using the equations.
As in the OBJ language [27] that Maude extends, functional modules can be unparameterized, or they can be parameterized with functional theories as their parameters. Core Maude only allows unparameterized modules, although, as further explained in Section 2.3 and also illustrated in some of the following examples, such unparameterized modules can import other modules to form module hierarchies. Parameterized modules are supported in Full Maude, as discussed in Section 3.5.
The equational logic on which Maude functional modules are based is an extension of order-sorted equational logic called membership equational logic [41, 5]; we discuss this and give more details about the semantics of functional modules in Section 4.1. For the moment, it suffices to say that, in addition to supporting sorts, subsort relations, and overloading of function symbols, functional modules also support membership axioms, a generalization of sort constraints [43] in which a term is asserted to have a certain sort if a condition consisting of a conjunction of equations and of unconditional membership tests is satisfied. Such membership axioms can be used to define partial functions, that become defined when their arguments satisfy certain equational and membership conditions.
Figure 1: An Automaton.
We can illustrate these ideas, as well as Maude's support for mixfix user-definable syntax, with a module PATH that forms paths over a graph. Consider the graph in Figure 1. This graph describes an automaton whose states are the nodes of the graph, and whose transitions are the labeled edges. A behavior of the automaton is a path in the graph, that is, a concatenation of transitions such that the target state of one transition becomes the source state of the next transition. Of course, not all random concatenations of edges are legal paths, that is, not all strings of edges are behaviors of the automaton. The PATH module below axiomatizes the automaton and characterizes in a computable way its paths by means of a path concatenation operation, a length function, and source and target functions, together with appropriate axioms in membership equational logic.
fmod PATH is
protecting MACHINE-INT .
sorts Edge Path Path? Node .
subsorts Edge < Path < Path? .
ops n1 n2 n3 n4 n5 : -> Node .
ops a b c d e f : -> Edge .
op _;_ : Path? Path? -> Path? [assoc] .
ops source target : Path -> Node .
op length : Path -> MachineInt .
var E : Edge .
var P : Path .
cmb (E ; P) : Path if target(E) == source(P) .
ceq source(E ; P) = source(E) if E ; P : Path .
ceq target(P ; E) = target(E) if P ; E : Path .
eq length(E) = 1 .
ceq length(E ; P) = 1 + length(P) if E ; P : Path .
eq source(a) = n1 .
eq target(a) = n2 .
eq source(b) = n1 .
eq target(b) = n3 .
eq source(c) = n3 .
eq target(c) = n4 .
eq source(d) = n4 .
eq target(d) = n2 .
eq source(e) = n2 .
eq target(e) = n5 .
eq source(f) = n2 .
eq target(f) = n1 .
endfm
The module is introduced with the functional module syntax fmod...endfm and has a name, PATH. It imports a predefined module of machine integers with the declaration protecting MACHINE-INT (for more on predefined modules see Section 2.4, and for more on module importation and module hierarchies see Section 2.3). The sorts and subsort relations of this module are introduced by a sort declaration and a subsort declaration. Sorts--we could have called them types instead--are used to classify data. A subsort relation between two sorts is interpreted as a set-theoretic inclusion, that is, it means that the data of the subsort is included in that of the supersort. For example, the subsort declaration
subsorts Edge < Path < Path? .
op _;_ : Path? Path? -> Path? [assoc] .
Except for the conditional membership axiom for path concatenation, and the use of sort tests in the conditions of some equations, that we explain below, the rest of the module should be straightforward. Some nodes and edges are declared, plus source, target, and length functions, all of them with standard prefix notation, that is also allowed as a simpler choice of user-definable syntactic form. Then equations are given, defining the semantics of the operations. Each equation is introduced by the keyword eq, or ceq for conditional equations, and having variables of appropriate sorts previously declared with var declarations. The equations are then used from left to right by the Maude engine to simplify each expression to its canonical form, that is, to evaluate each expression to its corresponding value.
In general, an operator can be declared with the keyword op3 followed by its syntactic form, followed by a colon, followed by the list4 of sorts for its arguments (called the operator's arity), followed by ->, followed by the sort of its result (called the operator's coarity). The operator can have some attributes, such as the assoc attribute for path concatenation, which indicate some equational axioms satisfied by the operator and used for term matching, or some syntactic information for parsing purposes, or some other information. All such attributes are declared within a single pair of enclosing square brackets after the sort of the result and before the ending period.
The syntactic form of the operator is a string of characters5. If no underbar character occurs in the string--as in the case of the source, target, and length functions--then the operator is declared in prefix form. If underbar characters occur in the string, then their number must coincide with the number of sorts declared as arguments of the operator. The operator is then in mixfix form, with the n-th underbar indicating the place where arguments of the n-th sort must be placed in expressions formed with that operator. There may or may not be any other characters before or after any of the underbars. If no other characters appear, we say that the operator has been declared with empty syntax. For example, we could have instead declared the path concatenation operator with empty syntax as
op __ : Path? Path? -> Path? .
The ruling out of nonsensical concatenations is achieved by the conditional membership axiom6
cmb (E ; P) : Path if target(E) == source(P) .
target(P) == source(Q) .
cmb (P ; Q) : Path if target(P) == source(Q) .
All variables in righthand sides of equations should also appear in the corresponding lefthand sides. The conditions in conditional membership axioms--respectively, in conditional equations--should only involve variables appearing in the corresponding membership predicate--respectively, in the corresponding lefhand side. As the above example shows, the user can use the Boolean-valued, built-in equality predicate _==_ and sort predicates such as _: Path, and in general Boolean combinations of such predicates or of other user-defined Boolean-valued expressions, in conditions of equations and membership axioms7. See Sections 2.4.1 and 4.1 for more details on the built-in equality and inequality predicates, and for a discussion of why negations and Boolean combinations of built-in equality and membership predicates in conditions--which would seem to go beyond Horn logic--are unproblematic under appropriate Church-Rosser and terminating assumptions about the specification.
Note that the functions source, target, and length are only defined on legal paths, so that on nonsensical paths they will return an unevaluated expression in an error supersort. For the first two functions the error supersort is Error(Node) above the sort of nodes, and for the third it is Error(MachineInt) above the sort of machine integers. Such expressions are very informative error messages. The Maude system automatically adds these error supersorts above each of the connected components of the poset of sorts declared by the user, using the set of maximal sorts in each connected component to qualify the corresponding error sort; such error sorts are called kinds in the theory of membership algebras (see Section 4). In this example there is a third connected component in the subsort ordering poset, namely, the connected component involving the sorts Edge, Path, and Path?, and therefore a third error supersort, Error(Path?), is also added. Note that, even though Path? was introduced by the user with the purpose of catching errors, Maude always adds a new error supersort above each connected component. This is because, conceptually, an error supersort is really not a sort, but a kind. The point is that sorts are user-defined, while kinds are implicitly associated with connected components of sorts and are automatically added by Maude in the form of "error supersorts". The Maude system also lifts automatically to the error supersorts all the operators involving sorts of the corresponding connected components to form error expressions. Such error expressions allow us to give expressions to be evaluated the benefit of the doubt: if when they are simplified they have a legal sort, then they are ok; otherwise, the fully simplified error expression is returned as an error message.
As illustrated by a few sample evaluations and their results, expressions formed with the operators declared in the module can be evaluated with the reduce command--red in abbreviated form. In the reduction process the equations are used from left to right as rules of simplification, and the membership axioms are also used to lower the sort of each expression as much as possible. When the expression has the lowest possible sort and cannot be simplified anymore using the equations, it is returned together with its lowest sort as the result.
Maude> red (b ; c ; d) . result Path: (b ; c ; d) Maude> red length(b ; c ; d) . result NzMachineInt: 3 Maude> red (a ; b ; c) . result Path?: (a ; b ; c) Maude> red source(a ; b ; c) . result Error(Node): source(a ; b ; c) Maude> red target(a ; b ; c) . result Error(Node): target(a ; b ; c) Maude> red length(a ; b ; c) . result Error(MachineInt): length(a ; b ; c)