

Theories can be used to declare the interface requirements for parameterized modules. Modules can be parameterized by one or more theories. All theories appearing in the interface have to be labeled in such a way that their sorts can be uniquely identified. The general form for the interface of a parameterized module is [ X1 :: T1 , ... , Xn :: Tn ], where X1...Xn are the labels and T1...Tn are the names of the parameter theories. Thus, the syntax of the interface of parameterized modules is given by the following declarations.
op _::_ : Token ModExp -> Parameter [prec 40 gather (e &)] . subsort Parameter < ParameterList . op _,_ : ParameterList ParameterList -> ParameterList [assoc] . op _[_] : Token ParameterList -> ModuleName .
In the current version of Full Maude all the sorts coming from theories in the interface must be qualified by their labels, even if there is no ambiguity. If Z is the label of a parameter theory T, then each sort S in T has to be qualified as S.Z. Since, as we will see in Section 3.5.3, operator maps affect entire families of subsort-overloaded operators, there cannot be subsort overloading between an operator declared in a theory being used as parameter of a parameterized module and an operator declared in the body of the parameterized module, or between operators declared in two parameter theories of the same module. Thus, the parameterized module SIMPLE-SET, with TRIV as interface can be defined as follows.
(fmod SIMPLE-SET[X :: TRIV] is
sorts Set NeSet .
subsorts Elt.X < NeSet < Set .
op mt : -> Set .
op __ : Set Set -> Set [assoc comm id: mt] .
op __ : NeSet NeSet -> NeSet [assoc comm id: mt] .
var E : Elt.X .
eq E E = E .
endfm)
Note that, as discussed in Section 3.3, in Maude--unlike OBJ3--sorts are not systematically qualified by their module name. In the case of OBJ3, importing, for example, sets or lists of different elements introduces repeated sorts Set or List and operators that must be qualified by the names of the submodules they come from, that is, by module expressions often of considerable length. Of course, in OBJ3 it is possible to rename all these items. But this means that, to avoid the burden of long qualifications by module expressions, we have to include explicitly many more renamings than we would like.
The convention of not qualifying sorts may be particularly weak when dealing with parameterized modules. However, given that Maude supports ad-hoc overloading and that constants can be qualified in order to be disambiguated, the problem of ambiguity in a signature is reduced to collisions of sorts. Our proposal consists in qualifying parameterized sorts, not with the module expression they belong to, but with the name of the view or views used in the instantiation of the parameterized module. In the current version of Full Maude, we assume that all views are named, and that these names are the ones used in the qualification. Specifically, in the body of a parameterized module M[ X1 :: T1 , ... , Xn :: Tn ], any sort S can be written in the form S[X1,...,Xn]. When the module is instantiated with views V1,...,Vn then this sort becomes S[V1,...,Vn]. Note that the parameterization of sorts is optional. The above specification, for example, is perfectly valid.
The declarations needed to allow parameterized sorts are the following.
subsort ViewToken < ViewExp . op _,_ : ViewExp ViewExp -> ViewExp [assoc] . op _[_] : Sort ViewExp -> Sort [prec 40] .
Thus, the previous module to define sets could instead have been defined as follows.
(fmod SET[X :: TRIV] is
sorts Set[X] NeSet[X] .
subsorts Elt.X < NeSet[X] < Set[X] .
op mt : -> Set[X] .
op __ : Set[X] Set[X] -> Set[X] [assoc comm id: mt] .
op __ : NeSet[X] NeSet[X] -> NeSet[X] [assoc comm id: mt] .
var E : Elt.X .
eq E E = E .
endfm)
In the coming sections we will see how this qualification convention for the sorts of a parameterized module avoids many unintended collisions of sort names, thus making renaming practically unnecessary.
The module SET has only one parameter. In general, however, parameterized modules can have several parameters. It can furthermore happen that several parameters are declared with the same parameter theory, that is, we can have an interface of the form [X :: TRIV, Y :: TRIV] involving the theory TRIV. Therefore, parameters cannot be treated as normal submodules, since we do not want them to be shared when their labels are different. We regard the relationship between the body of a parameterized module and the interface of its parameters not as an inclusion, but as a module constructor which is evaluated generating renamed copies of the parameters, which are then included. For the above interface, two copies of the theory TRIV are generated, with names X :: TRIV and Y :: TRIV. In such copies of parameter theories sorts are renamed as follows: If Z is the label of a parameter theory T, then each sort S in T (for TRIV just the sort Elt) is renamed to S.Z. This is the reason why all occurrences of these sorts in the parameterized module must mention their corresponding renaming. In a future version of the system, this qualification will be necessary only in case of ambiguity.
Let us consider as an example the following module PAIR. Notice the use of the qualifications for the sorts coming from each of the parameters, and notice also the qualification of the sort Pair[X, Y].
(fmod PAIR[X :: TRIV, Y :: TRIV] is
sort Pair[X, Y] .
op <_;_> : Elt.X Elt.Y -> Pair[X, Y] .
op 1st : Pair[X, Y] -> Elt.X .
op 2nd : Pair[X, Y] -> Elt.Y .
var A : Elt.X .
var B : Elt.Y .
eq 1st(< A ; B >) = A .
eq 2nd(< A ; B >) = B .
endfm)
If a parameter theory is structured, this renaming process for parameter theories is carried out not only at the top level, but for the whole "theory part," that is, not renaming modules. Consider, for example, the following parameterized module defining a lexicographical ordering on pairs of elements of a totally ordered set.
(fmod TOSET-PAIR[X :: TOSET, Y :: TOSET] is
sort Pair[X, Y] .
op <_;_> : Elt.X Elt.Y -> Pair[X, Y] .
op _<_ : Pair[X, Y] Pair[X, Y] -> Bool .
op 1st : Pair[X, Y] -> Elt.X .
op 2nd : Pair[X, Y] -> Elt.Y .
var A A' : Elt.X .
var B B' : Elt.Y .
eq 1st(< A ; B >) = A .
eq 2nd(< A ; B >) = B .
eq < A ; B > < < A' ; B' >
= (A < A') or (A == A' and B < B') .
endfm)
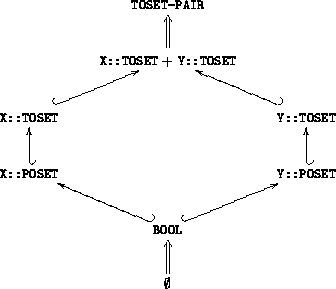
Representing by
 the inclusion relations between modules
and theories, and by => the initiality constraints, we can depict
the resulting structure as follows.
the inclusion relations between modules
and theories, and by => the initiality constraints, we can depict
the resulting structure as follows.
where we have two copies not only of TOSET but also of the POSET subtheory.
An object-oriented parameterized module defining a stack of elements can be defined as follows. We define a class Stack[X]37 as a linked sequence of node objects. Objects of class Stack[X] only have an attribute first, containing the identifier of the first node in the stack. If the stack is empty the value of the first attribute is null. Each object of class Node[X] has an attribute next holding the identifier of the next node--which will be null if there is no next node--and an attribute contents to store a value of sort Elt.X. Notice that the identifiers of the nodes are of the form o(S,N), where S is the identifier of the stack object to which the node belongs, and N is a natural number. The messages push, pop and top have as their first argument the identifier of the object to which they are addressed, and will cause, respectively, the insertion at the top of the stack of a new element, the deletion of the top element, and the sending of a response message elt containing the element at the top of the stack to the object making the request.
(omod STACK[X :: TRIV] is
protecting MACHINE-INT .
protecting QID .
subsort Qid < Oid .
class Node[X] | next : Oid, contents : Elt.X .
class Stack[X] | first : Oid .
msg _push_ : Oid Elt.X -> Msg .
msg _pop : Oid -> Msg .
msg _top_ : Oid Oid -> Msg .
msg _elt_ : Oid Elt.X -> Msg .
op null : -> Oid .
op o : Oid MachineInt -> Oid .
vars O O' O'' : Oid .
var E : Elt.X .
var N : MachineInt .
rl [top] : *** top on a nonempty stack
< O : Stack[X] | first : O' >
< O' : Node[X] | contents : E >
(O top O'')
=> < O : Stack[X] | >
< O' : Node[X] | >
(O'' elt E) .
rl [push1] : *** push on a nonempty stack
< O : Stack[X] | first : o(O, N) >
(O push E)
=> < O : Stack[X] | first : o(O, N + 1) >
< o(O, N + 1) : Node[X] |
contents : E, next : o(O, N) > .
rl [push2] : *** push on an empty stack
< O : Stack[X] | first : null >
(O push E)
=> < O : Stack[X] | first : o(O, 0) >
< o(O, 0) : Node[X] | contents : E, next : null > .
rl [pop] : *** pop on a nonempty stack
< O : Stack[X] | first : O' >
< O' : Node[X] | next : O'' >
(O pop)
=> < O : Stack[X] | first : O'' > .
endom)
We may want to define stacks not storing data elements of a particular sort, but actually objects in a particular class. We can define an object-oriented module with the intended behavior as a parameterized module STACK2 parameterized by the object-oriented theory CELL, presented in Section 3.5.1, as follows.
(omod STACK2[X :: CELL] is
protecting MACHINE-INT .
protecting QID .
subsort Qid < Oid .
class Node[X] | next : Oid, node : Oid .
class Stack[X] | first : Oid .
msg _push_ : Oid Oid -> Msg .
msg _pop : Oid -> Msg .
msg _top_ : Oid Oid -> Msg .
msg _elt_ : Oid Elt.X -> Msg .
op null : -> Oid .
op o : Oid MachineInt -> Oid .
vars O O' O'' O''' : Oid .
var E : Elt.X .
var N : MachineInt .
rl [top] : *** top on a nonempty stack
< O : Stack[X] | first : O' >
< O' : Node[X] | node : O'' >
< O'' : Cell.X | contents : E >
(O top O''')
=> < O : Stack[X] | >
< O' : Node[X] | >
< O'' : Cell.X | >
(O'' elt E) .
rl [push1] : *** push on a nonempty stack
< O : Stack[X] | first : o(O, N) >
(O push O')
=> < O : Stack[X] | first : o(O, N + 1) >
< o(O, N + 1) : Node[X] |
next : o(O, N), node : O' > .
rl [push2] : *** push on an empty stack
< O : Stack[X] | first : null >
(O push O')
=> < O : Stack[X] | first : o(O, 0) >
< o(O, 0) : Node[X] | next : null, node : O' > .
rl [pop] : *** pop on a nonempty stack
< O : Stack[X] | first : O' >
< O' : Node[X] | next : O'' >
(O pop)
=> < O : Stack[X] | first : O'' > .
endom)